|
|
최근 질답란을 보니 unicode와 한글, utf-8등에 대해서 혼란을 일으키시는 분이 많은거 같아서 정리를 해볼겸 간단히 글을 써봅니다. 이 글을 쓴 목적은 방대한 양의 정보를 주기 위함이 아니고 간단히 읽고서 코딩이 가능할 정도의 상식을 포함하기 위함입니다. 한글에 대해서 자세히 알고 싶으신 분들은 추가 정보를 찾아보셔야합니다.
---------------------------------------------
Q1. 왜 한글 표현하는데, 이렇게 복잡한게 많나요.
Q2. 완성형과 조합형은 무엇인가요?
Q3. MBCS와 완성형의 관계는?
Q4. 완성형과 CP949, EUC-KR
Q5. UNICODE란?
Q6. UNICODE에서 encoding이란?
Q7. UTF-8, UTF-16, ucs2, ucs4
Q8. wchar와 char
Q9. 참조링크
A1. 근본적으로 한글은 조합을 해서 글자를 만들어내기 때문입니다.
훈민정음의 제자원리를 따지지 않아도 과학적이고 편리한 글인데 디지털 세상에서는 홑글자로 이루어진 알파벳보다는 프로그래밍하기에 불편합니다. 하지만 상대적으로 불리한것이지, 중국이나 일본처럼 아주 복잡한것은 아닙니다.
A2. 완성형은 글자 자체를 하나의 형태로 보고
코드화한 것이고 조합형은 총 한글자로 표시되는 바이트(보통 2바이트)내에서 비트를 나누어서 초성, 중성, 종성을 할당해서 글자를 표현하는 방식입니다. 완성형은 현재 ksx1001 (옛 표준이름 KSC5601)이라는 표준 많이 쓰이고 있으며 조합형은 거즘 쓰이지 않습니다.
조합형도 여러가지가 있어 논란이되다가 결국엔 1987년에 완성형만이 표준으로 되었습니다. 후에 상용 조합형도 표준으로 들어갔으나, 이미 표준이 된 완성형만이 널리 쓰이게 되었고 2350자밖에 표현이 안되는 완성형이 윈도에서 쓰이므로 지금까지도 가장 널리쓰이는 글자 표현 체계가 되었습니다.
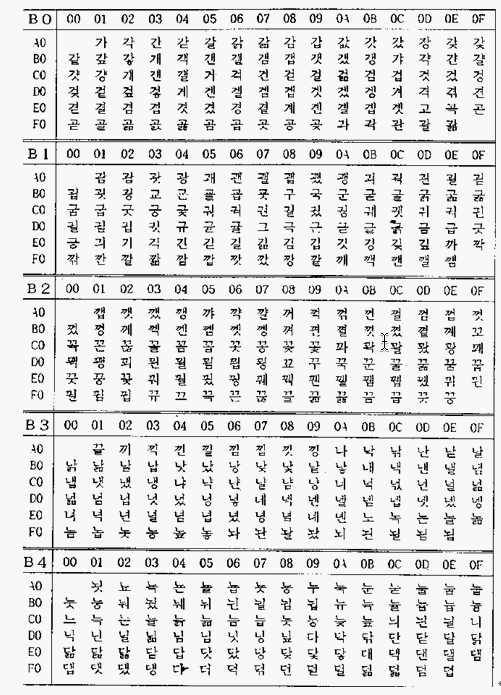
<완성형 코드의 일부>

<조합형 코드표의 일부>
A3. MBCS는 visual c++설정에서 보면 있는데
multibyte character set의 줄임말입니다. 바이트 여러개로 코드셋을 표현하겠다는 말인데 1바이트는 256개의 가짓수만 가지므로 한글의 총 조합은 11172가짓수인데 턱없이 부족합니다. 그래서 한글이 2바이트 (총 65536개의 가짓수)를 가지는 MBCS를 이용합니다. MBCS로도 조합형을 쓸수는 있지만 대부분 완성형을 씁니다.
A4. EUC 계열은 유닉스 계열에서 나온것으로
윈도 보다 더 오래동안 지역화 및 한글화문제를 겪어서 빨리 대처를 할수 있었습니다. 그래서 EUC-KR하면 한국 코드인데, 이때의 표준인 완성형과 일치합니다. 즉, EUC-KR = 완성형 입니다. 윈도에서는 codepage 949가 완성형인데, 변화를 한번 겪어서 UHC(통합완성형)이라는 이름으로 불리고 있습니다. CP949 = UHC로 보시면 됩니다.
이 통합 완성형은 완성형에서 표현할수 없는 "똠"과 같은 글자를 넣어서 더 많은 가짓수의 한글 글자를 표현할수 있으나, 역시 완성형이라는 한계를 가지고 고대 한글 표현이나 sort등에 불리합니다. (EUC-KR <= CP949)
A5. 세계 여러나라에서 공통되게 겪는 문제중에 하나였는데 (일본같은경우도 shift-jis등 여러 표현체계가 많았고 중국도 같은 문제를 겪었음) 이런 문제를 해결하고자 나온 글자 형태입니다. 즉 모든 글자 표현체계를 하나로 통합하겠다고 해서 이름 그 자체도 unicode입니다. 한글로 번역해보면 단일체계 정도될까요.
unicode 1.0에서는 몇가지 문제가 있어서 표현이 잘안되는 글자가 있었으며 unicode 2.0에서는 완벽히 한글이 표현 됩니다.(고어 포함) 현재는 unicode 5.0 입니다.
A6. unicode 자체는 어떤 특정한 바이트 형태를 지정하지 않습니다.
따라서 encoding이라는게 필요합니다. 그러니까 unicode != UTF-8이죠. unicode encoding중에 하나가 UTF-8은 될수 있습니다. 예를 들면 unicode "위"(U+C704)를 UTF-8로 표현하면 EC 9C 84 가 됩니다. 현재 unicode에서 널리쓰이는 encoding은 UTF-8, UTF-16, UCS2, UCS4등이 있습니다. 왜 하나의 표현체계로 하자면서, 이런 많은 encoding이 생겼냐면 전환하는데 비용이 너무 많이 들고 서양쪽의 체계에서 불이익이 많기때문입니다.
'A' 하나 표현하는데 현재는 1바이트면 될것을 2~4바이트 이상으로 해야하니까, 알파벳만 쓰는측에서는 쓰지도 않을것때문에 메모리 및 저장장치 공간을 낭비해야하고 이전비용이 많이 들어갑니다. 그래서 현재는 UTF-8이 주도적으로 쓰입니다. UTF-8은 흔히 말하는 숫자, 영문자 (ascii대역)에서는 그대로 1바이트로 쓸수있고, 나머지는 가변이라서 공간을 아끼면서도 실리를 찾을수 있습니다.
A7. 이 부분은 직접 답을 달지 않고 링크로 남기겠습니다.
http://ko.wikipedia.org/wiki/%EC%9C%A0%EB%8B%88%EC%BD%94%EB%93%9C
http://ko.wikipedia.org/wiki/UTF-8
http://ko.wikipedia.org/wiki/UTF-16
A8. 흔히들 TCHAR매크로를 많이 쓰실것입니다.
유니코드와 MBCS를 오갈때 편리한데. 유니코드일때 TCHAR은 wchar로 변합니다. wchar은 이름에서 알다시피 wide char입니다. 이 wide char은 2바이트 이상의 글자 체계를 표현하고자 만들었는데 간혹 실수를 하시는 분이 있는데 char자체는 바이트가 몇바이트다 라는 고정크기가 없습니다. 따라서 여러플랫폼간에 이식을 하실때는 주의하셔야합니다.
A9. 이 글을 쓰면서 여러 문서를 참조했는데
이 두개은 꼭 읽어두셔야합니다.
UNICODE사용에 관한 FAQ
http://www.devpia.com/Forum/BoardView.aspx?no=6897&ref=6897&forumname=VC_LEC
컴퓨터속의 한글
http://b.mytears.org/2005/01/101
ksc5601과 그 표준 정의에 대해서
http://trade.chonbuk.ac.kr/~leesl/code/10646.html
한글과 관련된 토론
http://forum.standardmag.org/viewtopic.php?pid=3866
utf8에 관한글
http://khero.tistory.com/tag/UTF8
ksc5601에 관한글
http://web.edunet4u.net/~han0416/%ED%95%98%EB%93%9C%EC%9B%A8%EC%96%B4%20%EA%B0%95%EC%A2%8C/chapter2/ksc5601_87s.htm
'IT 세상 > 자바세상' 카테고리의 다른 글
| 자바 정규식 (0) | 2008.03.10 |
|---|---|
| eclipse에서의 JAVA Compile 환경 설정하기 (0) | 2008.03.05 |
| JAVA에서 쿠키 사용하기 (0) | 2007.12.13 |
| JAVA DB연결 (0) | 2007.12.13 |
| JAVA 에러대처 (0) | 2007.12.13 |